Connor ShortenRelease Notes — AI-Native Databases Episode 1: Andy PavloThe first episode of our AI-Native Database series! An overview of topics around Self-Driving Databases and many more!Dec 19, 20231Dec 19, 20231
Connor ShortenRelease Notes — Nils Reimers on Cohere Search AI, Weaviate Podcast #63New topics in Search! Covering Cohere Rerankers, Metadata in Search, Chunking and Long Document Representations, RAG, and more!Aug 16, 2023Aug 16, 2023
Connor ShortenHow to add Timestamps to Data Objects in Weaviate and then Sort by TimeHey everyone, I wanted to just quickly document this in case someone else finds themself working on a similar problem.Sep 27, 2022Sep 27, 2022
Connor ShortenANN Benchmarks with Etienne Dilocker — Weaviate podcast #16Written summaries of discussed topics in Approximate Nearest Neighbor (ANN) benchmarking! Billion-Scale Vector Search!May 27, 2022May 27, 2022
Connor ShortenDeep Learning with Code DataCode languages, such as Python or Java, have become a core application area of Deep Learning. OpenAI and GitHub have recently unveiled…Jul 15, 2021Jul 15, 2021
Connor ShortenAI Weekly Update Preview — April 12th, 2021This article presents a few salient quotes from each of the papers that will be covered on the next AI Weekly Update on Henry AI Labs!Apr 9, 2021Apr 9, 2021
Connor ShortenAI Weekly Update — December 28th, 2020Computer Vision has been taken over by Transformers!Dec 28, 2020Dec 28, 2020
Connor ShortenTokenizing CORD-19 with NLTKScientific overload is one of the toughest challenges facing scientists today. As Machine Learning researchers, we constantly complain…Nov 27, 2020Nov 27, 2020
Connor ShorteninTowards Data ScienceSelf-Training for Natural Language Understanding!This article explains the use of Self-Training in Natural Language Understanding, achieving impressive performance gains!Oct 27, 2020Oct 27, 2020
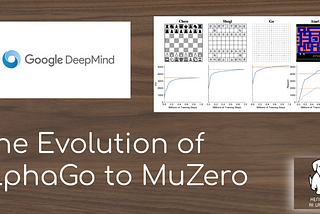
Connor ShorteninTowards Data ScienceThe Evolution of AlphaGo to MuZeroDeepMind’s MuZero algorithm reaches superhuman ability in 57 different Atari games. This article will explain the context leading up to it!Jan 17, 2020Jan 17, 2020